
How To Scrape The GitHub Organizations You Contributed To Using Python
A scraping tutorial with a real world use-case
Why Do I Want to Scrape These GitHub Organizations?¶
As I built my own website, I wanted to display my GitHub contributions without the need of changing them by hand. The GitHub API provides you a lot of things, but I was not able to figure out how I can (easily) get the names of the organizations I contributed to. That's why I decided to scrape them from my GitHub profile.
In this article, I will show you how I have done that and guide you through the whole process.
Requirements¶
Note: The article uses Python 3.8.2 (CPython). You can find the code used in the article on GitHub.
In order to follow the article you need to install a few dependencies.
Create a new file in your current directory and name it requirements.txt.
Open it in your favourite text editor and paste the following dependencies into it:
beautifulsoup4==4.9.0
lxml==4.5.0
requests==2.23.0
We use requests to get the websites content and lxml and beautifulsoup4 to extract the information we need.
If you do not want to mess up your Python installation, create a virtual environment in your current directory and activate it:
$ python -m venv .venv
$ source .venv/bin/activate
Note: You may have to type
python3to use the correct Python version on your computer. If you want to know more about virtual environments, consider visiting the attached resources [1].
Then you can install the packages listed in the requirements.txt file using pip:
$ python -m pip install -r requirements.txt
Find the HTML Tags You Need¶
First of all, you need to know where you can find the information you want to have. In this case we want to get the GitHub organizations a certain user has contributed to, so we are visiting a user's GitHub page. Scrolling down to the contributions section will shows us something similar to:
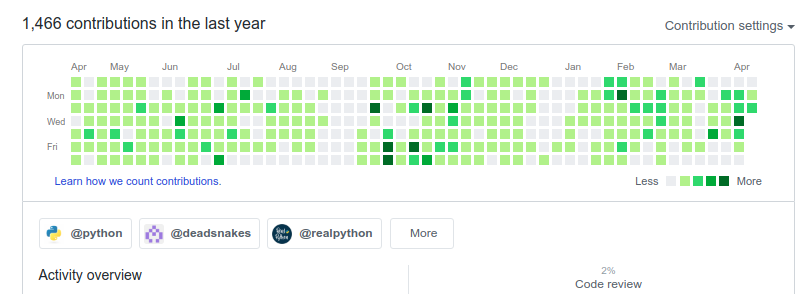
Let's inspect the HTML code of this site by opening your browser's developer tools and navigating to the desired element.
You can right-click on one of the organizations and click on Inspect, Inspect Element or something similar.
In your browser's developer tools you can see that all organizations the user has contributed to are hyperlinks in <a>-tags within a <nav>-element.
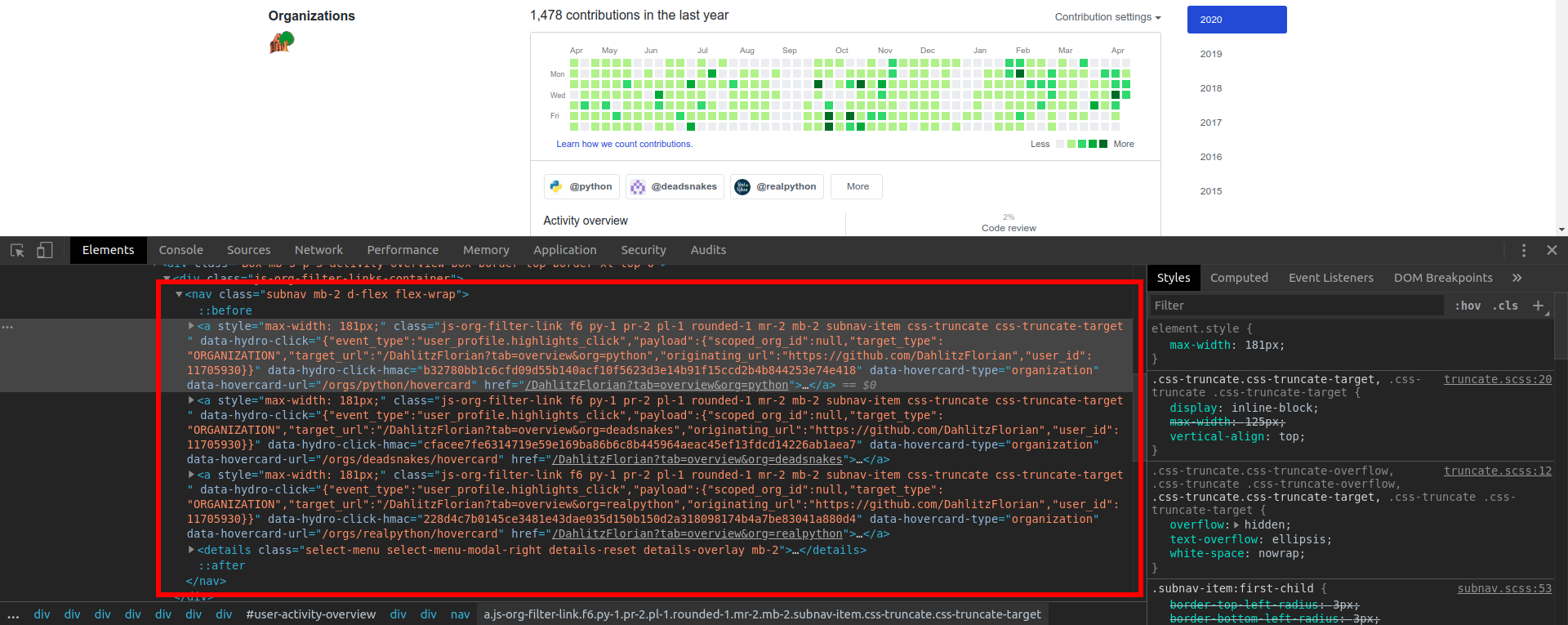
We are mostly interested in the <nav>-element as it is the container for the organizations, so we save the element's classes for later usage:
orgs_nav_classes = "subnav mb-2 d-flex flex-wrap"
You may have noticed that we ignored the organizations listed when you click on More.
These organizations are also wrapped in hyperlinks and with the later approach, we can extract them as well.
Instead of using the profile page for scraping, we use this page for it because it is (as far as I know) more reliable concerning HTML-code changes.
The orgs_nav_classes are still the same.
In your working directory, create a scrape_github_orgs.py file and paste the following code into it.
# scrape_github_orgs.py
import requests
from bs4 import BeautifulSoup
from bs4.element import ResultSet
orgs_nav_classes = "subnav mb-2 d-flex flex-wrap"
def get_user_org_hyperlinks(username: str) -> ResultSet:
url = f"https://github.com/users/{username}/contributions"
page = requests.get(url)
soup = BeautifulSoup(page.content, "html.parser")
nav = soup.find("nav", class_=orgs_nav_classes)
tmp_orgs = nav.find_all("a")
return tmp_orgs
print(get_user_org_hyperlinks("DahlitzFlorian"))
First, we import everything we need.
For one thing, these are the requests library as well as the BeautifulSoup-class from the bs4 package (beautifulsoup4 you remember?).
Subsequently, we define a function get_user_org_hyperlinks(), which takes a username as the only argument and returns all hyperlinks in the <nav>-element with the orgs_nav_classes classes.
In the last line, we print the result of calling get_user_org_hyperlinks() to see what is returned.
Executing the script may result in:
$ python scrape-github-orgs.py
[<a class="js-org-filter-link f6 py-1 pr-2 pl-1 rounded-1 mr-2 mb-2 subnav-item css-truncate css-truncate-target" data-hovercard-type="organization" data-hovercard-url="/orgs/python/hovercard" data-hydro-click='{"event_type":"user_profile.highlights_click","payload":{"scoped_org_id":null,"target_type":"ORGANIZATION","target_url":"/DahlitzFlorian?tab=overview&org=python","originating_url":"https://github.com/users/DahlitzFlorian/contributions","user_id":null}}' data-hydro-click-hmac="3663f0f1c5ecdf3ad7c4ccbf2ecaea5470a15408175ebcb137f286fd900fc30b" href="/DahlitzFlorian?tab=overview&org=python" style="max-width: 181px;">
<img alt="" class="avatar mr-1" height="20" src="https://avatars1.githubusercontent.com/u/1525981?s=60&v=4" width="20"/>
@python
</a>, <a class="js-org-filter-link f6 py-1 pr-2 pl-1 rounded-1 mr-2 mb-2 subnav-item css-truncate css-truncate-target" data-hovercard-type="organization" data-hovercard-url="/orgs/deadsnakes/hovercard" data-hydro-click='{"event_type":"user_profile.highlights_click","payload":{"scoped_org_id":null,"target_type":"ORGANIZATION","target_url":"/DahlitzFlorian?tab=overview&org=deadsnakes","originating_url":"https://github.com/users/DahlitzFlorian/contributions","user_id":null}}' data-hydro-click-hmac="2e0501a07d2125d7a4baad8faa6ad0c122f0f666c517db46acaed474cc87689b" href="/DahlitzFlorian?tab=overview&org=deadsnakes" style="max-width: 181px;">
<img alt="" class="avatar mr-1" height="20" src="https://avatars3.githubusercontent.com/u/31392125?s=60&v=4" width="20"/>
@deadsnakes
</a>, <a class="js-org-filter-link f6 py-1 pr-2 pl-1 rounded-1 mr-2 mb-2 subnav-item css-truncate css-truncate-target" data-hovercard-type="organization" data-hovercard-url="/orgs/realpython/hovercard" data-hydro-click='{"event_type":"user_profile.highlights_click","payload":{"scoped_org_id":null,"target_type":"ORGANIZATION","target_url":"/DahlitzFlorian?tab=overview&org=realpython","originating_url":"https://github.com/users/DahlitzFlorian/contributions","user_id":null}}' data-hydro-click-hmac="7d9cf37efc7d25bf36c85a17b01f15138f6261575347d3f139283056adce6043" href="/DahlitzFlorian?tab=overview&org=realpython" style="max-width: 181px;">
<img alt="" class="avatar mr-1" height="20" src="https://avatars1.githubusercontent.com/u/5448020?s=60&v=4" width="20"/>
@realpython
</a>, <a class="d-block select-menu-item wb-break-all js-org-filter-link" data-hydro-click='{"event_type":"user_profile.highlights_click","payload":{"scoped_org_id":null,"target_type":"ORGANIZATION","target_url":"/DahlitzFlorian?tab=overview&org=PyCQA","originating_url":"https://github.com/users/DahlitzFlorian/contributions","user_id":null}}' data-hydro-click-hmac="2080f6ec3d42f9ac04eabafad7c72805d26acb10c822037397fd5bd1dafd5da0" href="/DahlitzFlorian?tab=overview&org=PyCQA" role="menuitem" style="padding: 8px 8px 8px 30px;">
<img alt="" class="select-menu-item-icon mr-2" height="20" src="https://avatars1.githubusercontent.com/u/8749848?s=60&v=4" width="20"/>
<div class="select-menu-item-text css-truncate css-truncate-target" style="max-width: 95%;">@PyCQA</div>
</a>]
Let's move on to the extraction phase.
Extract the Necessary Information¶
Remember, we want to get the names of the GitHub organizations a certain user has contributed to.
We already fetched the hyperlinks containing the organization names.
However, these hyperlinks have a bunch of unnecessary classes and attributes we do not need, hence we are going to cleaning it up.
We utilize a Cleaner() from the lxml package (lxml.html.clean.Cleaner) in order to clean the hyperlinks.
First, we will remove all unnecessary attributes.
To this end, we create a new instance of the Cleaner-class and tell it to only save the attributes (safe_attrs_only=True) assigned to safe_attrs.
The attributes to be saved need to be immutable, thus we use a frozenset.
from lxml.html import clean
cleaner = clean.Cleaner()
cleaner.safe_attrs_only = True
cleaner.safe_attrs = frozenset(["class", "src", "href", "target"])
The three lines of code above are only defining our cleaner but do not clean the actual HTML yet.
This will happen in a later stage.
Next, we compile a regular expression matching all HTML-tags.
Therefore, we make use of Python's re-module.
import re
html_tags = re.compile("<.*?>")
Finally, we start cleaning the hyperlinks and build them the way we need them.
orgs = []
for org in tmp_orgs:
tmp_org = str(org)
org_name = re.sub(
html_tags,
"",
re.search(r"<a(.*)@(.*)</a>", tmp_org, flags=re.DOTALL).group(2).strip(),
)
orgs is a list, which will contain the hyperlinks to the GitHub organizations as we want them to be displayed on our website.
The list will be filled while looping over each hyperlink we scraped.
In the above code snippet we are iterating over all hyperlinks representing a single organization.
As we need strings and not bs4-elements, we convert each hyperlink to a string and save it to a local variable called tmp_org.
Subsequently, we use the re-module to extract the organization's name from the hyperlink by utilizing its sub() function.
Note: If you want to know more about regular expressions in Python, I can recommend the regular expression tutorial from DataCamp [2]. If you are only searching for a regular expression cheat sheet, checkout the ones from dataquest.io [3].
Now, we have the names of the organizations - great!
Let's construct HTML-hyperlinks in a form we can use on our website.
Therefore, we first convert the old hyperlink string tmp_org into a lxml tree by using its lxml.html.fromstring() function.
Remember:
tmp_orgis a local variable in thefor-loop, so this code is going to live inside thefor-loop later.
import lxml
from lxml import etree
tree = lxml.html.fromstring(tmp_org)
tree.attrib["href"] = f"https://github.com/{org_name}"
tree.attrib["class"] = "org"
tree.set("target", "_blank")
etree.strip_tags(tree, "div")
cleaned = cleaner.clean_html(tree)
orgs.append(lxml.html.tostring(cleaned).decode("utf-8"))
As each organization can be found at https://github.com/org_name, where org_name is the name of the organization, we can add the actual hyperlink by using the attrib dictionary of each tree-element.
To be able to style the hyperlinks later, we add a custom CSS-class to the hyperlink.
The class is named org.
As the hyperlink is pointing to an external resource, I want my browser to open the link in a new tab.
Consequently, the next line sets the attribute target="_blank" rel="noopener".
The line etree.strip_tags(tree, "div") strips all <div>-elements from the tree-element.
This is necessary given that the organizations listed under More have a <div> surrounding the organization name inside the hyperlink.
We don't need them, which is why they are stripped.
Two actions remaining: First, utilize the cleaner to strip all unnecessary attributes from the <a>-element.
Second, convert the tree-element into a string by using lxml.html.tostring() (we use UTF-8 as encoding) and append it to our orgs list.
Let's wrap everything into a function:
import re
from typing import List
import lxml
from bs4.element import ResultSet
from lxml import etree
from lxml.html import clean
def extract_orgs(tmp_orgs: ResultSet) -> List[str]:
cleaner = clean.Cleaner()
cleaner.safe_attrs_only = True
cleaner.safe_attrs = frozenset(["class", "src", "href", "target"])
html_tags = re.compile("<.*?>")
orgs = []
for org in tmp_orgs:
tmp_org = str(org)
org_name = re.sub(
html_tags,
"",
re.search(r"<a(.*)@(.*)</a>", tmp_org, flags=re.DOTALL).group(2).strip(),
)
tree = lxml.html.fromstring(tmp_org)
tree.attrib["href"] = f"https://github.com/{org_name}"
tree.attrib["class"] = "org"
tree.set("target", "_blank")
etree.strip_tags(tree, "div")
cleaned = cleaner.clean_html(tree)
orgs.append(lxml.html.tostring(cleaned).decode("utf-8"))
return orgs
We combine both extraction and scraping phase into a single function:
def get_user_orgs(username: str) -> List[str]:
tmp_orgs = get_user_org_hyperlinks(username)
return extract_orgs(tmp_orgs)
To see the result of our hard work, we print the result at the end of the script. The final script looks like this:
# scrape_github_orgs.py
import re
from typing import List
import lxml
import requests
from bs4 import BeautifulSoup
from bs4.element import ResultSet
from lxml import etree
from lxml.html import clean
orgs_nav_classes = "subnav mb-2 d-flex flex-wrap"
def get_user_org_hyperlinks(username: str) -> ResultSet:
url = f"https://github.com/users/{username}/contributions"
page = requests.get(url)
soup = BeautifulSoup(page.content, "html.parser")
nav = soup.find("nav", class_=orgs_nav_classes)
tmp_orgs = nav.find_all("a")
return tmp_orgs
def extract_orgs(tmp_orgs: ResultSet) -> List[str]:
cleaner = clean.Cleaner()
cleaner.safe_attrs_only = True
cleaner.safe_attrs = frozenset(["class", "src", "href", "target"])
html_tags = re.compile("<.*?>")
orgs = []
for org in tmp_orgs:
tmp_org = str(org)
org_name = re.sub(
html_tags,
"",
re.search(r"<a(.*)@(.*)</a>", tmp_org, flags=re.DOTALL).group(2).strip(),
)
tree = lxml.html.fromstring(tmp_org)
tree.attrib["href"] = f"https://github.com/{org_name}"
tree.attrib["class"] = "org"
tree.set("target", "_blank")
etree.strip_tags(tree, "div")
cleaned = cleaner.clean_html(tree)
orgs.append(lxml.html.tostring(cleaned).decode("utf-8"))
return orgs
def get_user_orgs(username: str) -> List[str]:
tmp_orgs = get_user_org_hyperlinks(username)
return extract_orgs(tmp_orgs)
print(get_user_orgs("DahlitzFlorian"))
Executing the script delivers the following output:
$ python scrape_github_orgs.py
['<a class="org" href="https://github.com/python" target="_blank" rel="noopener">\n<img class="avatar mr-1" src="https://avatars1.githubusercontent.com/u/1525981?s=60&v=4">\n @python\n</a>', '<a class="org" href="https://github.com/deadsnakes" target="_blank" rel="noopener">\n<img class="avatar mr-1" src="https://avatars3.githubusercontent.com/u/31392125?s=60&v=4">\n @deadsnakes\n</a>', '<a class="org" href="https://github.com/realpython" target="_blank" rel="noopener">\n<img class="avatar mr-1" src="https://avatars1.githubusercontent.com/u/5448020?s=60&v=4">\n @realpython\n</a>', '<a class="org" href="https://github.com/PyCQA" target="_blank" rel="noopener">\n<img class="select-menu-item-icon mr-2" src="https://avatars1.githubusercontent.com/u/8749848?s=60&v=4">\n@PyCQA\n</a>']
Congratulations, you scraped the GitHub organizations a user contributed to, extracted the information you need, and built your own hyperlinks in a form you can use for your website! Let's have a quick look at styling these hyperlinks for your website, so it looks like the badges on the GitHub profile.
Style the Information for Your Website¶
To display the actual hyperlinks we use Jinja2.
Here is a simple Jinja2-template in which a for-loop iterates over the list orgs and prints each element.
<!DOCTYPE html>
<html lang="en">
<head>
<title>GitHub Organizations</title>
<link rel="stylesheet" type="text/css" href="{{ url_for('static', filename='css/main.css') }}">
</head>
<body>
<div class="orgs">{% raw %}
{% for org in orgs %}
{{ org | safe }}
{% endfor %}
{% endraw %}</div>
</body>
</html>
I used a Flask-backend to serve the website (python -m pip install flask==1.1.2).
Checkout the article's GitHub repository to find the necessary code and directory-structure.
Let's add some style to our site:
div.orgs {
display: flex;
flex-direction: row;
flex-wrap: wrap;
align-items: center;
justify-content: center;
margin-top: 15px;
}
a.org {
background-color: #fff;
border: 1px solid #e1e4e8;
border-radius: 3px;
padding: 7px;
margin: 10px;
color: #586069;
text-decoration: none;
display: flex;
align-items: center;
}
a.org:hover {
background-color: #f6f8fa;
}
a.org > img {
margin-right: 5px;
max-height: 25px;
}
Serving the website via command-line shows the following result:

Summary¶
In this article you learned how to scrape information from a website, extract the information you need, and bring it in a form you can use for later visualization. As an example you scraped the GitHub organizations a certain user contributed to and displayed the styled badges in a Jinja2-template.
I hope you enjoyed reading the article. Feel free to share it with your friends and colleagues or reach out to me to provide feedback (contact information). Stay curious and keep coding!