
Machine Learning Overview
Get an overview of one of the most popular data science disciplines
Introduction¶
Over the past years, Machine Learning got more and more popular. Especially Python evolved to be the number one programming language used in the field of data science and machine learning. Every day, new insights are gained and resources are published.
For a newcomer to that field, it may be hard to navigate through the massive amount of information out there. The article at hand aims to give you a general overview of machine learning and its disciplines.
In essence, the field of machine learning can be divided into three subcategories:
- Supervised Learning
- Unsupervised Learning
- Reinforcement Learning
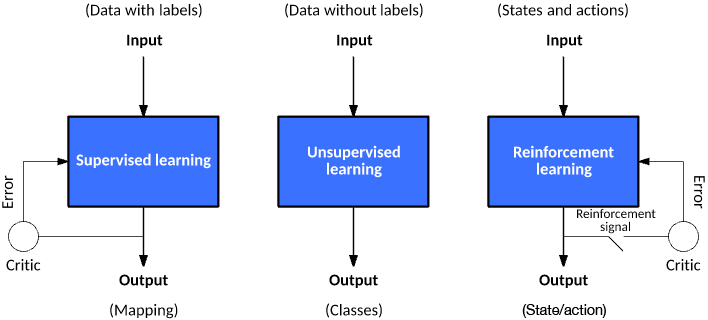
Info
The image (source) gives an overview of all three machine learning disciplines. We will have a closer look at all three of them.
Supervised Learning¶
Let's start with supervised learning. Supervised learning or supervised machine learning is defined by its use of labelled datasets to train algorithms that classify data or predict outcomes accurately.
Labelled data can be structured or unstructured, but it is important that each data point gets a meaningful label (a.k.a. tag, class or numeric value) assigned. Depending on the used approach, the labelled input data is split into training, test, and validation data, where the size of each can vary.
During the training phase, the training data is used to fit the model. This means that the model is adjusted to reduce the overall error. Simply put, the training data is used to tell the model the correct output, so it can compare its output with the target.
If the output of the model is the same as the one given by humans, nothing is changed. However, if both outputs are different, internal weights or constants (depending on the architecture and algorithms used) are adjusted. This is repeated until the model achieves a desired level of accuracy on the training data and can correctly predict the class label or numeric value for new instances. We will see how this is accomplished in a future article.
When the training is completed, the test phase is entered. The test data is used to check how well the model performs on data it hasn't seen yet.
At this point, we already got an overview of the different phases to create a supervised machine learning model. Let's become a little more concrete about when and how to use it. In essence, supervised learning consists of two types of problems:
- Regression
- Classification
Regression is used to understand the relationship between dependent and given (or independent) variables. Put differently, it is used to predict a numeric value. Common examples are predicting the price of a house based on its size or the sales revenue for a business.
On the contrary, classification uses an algorithm to put a data point into a category or to assign a label to it. A popular binary classification task is to classify emails as spam or not spam.
Unsupervised Learning¶
In contrast to supervised learning, unsupervised learning uses unlabelled data. This means that we as humans do not tell the model, what the correct output is. Mostly, because we don't know it (that's why we use unsupervised learning). The machine must figure out the correct answer without having a reference and must therefore discover unknown patterns in the data. The rest is pretty similar to supervised learning.
Unsupervised learning involves a couple of problem types. Clustering, association rules, and dimensionality reduction are only three of them. Frequent use-cases are customer segmentation, text summarization, face recognition, and recommender systems.
Reinforcement Learning¶
Reinforcement Learning is probably the most unexplored of the three machine learning subcategories.
In essence, the reinforcement agent (machine, model - you name it) is bound to learn from its experience, because no training dataset is present.
Suppose you place the agent in an unknown environment. There is a certain goal or reward that it needs to reach. The task at hand is to find a path to the reward without intermediate control. Along the way are many hurdles it needs to deal with.
How does the training look like?
The basic idea is that the agent has an initial state, so it is placed somewhere in the environment. It takes a step and returns the state. A human agent decides whether the move was good (reward) or bad (punish). In the end, the path with the highest reward (probably the most efficient way) is chosen.
A popular example of reinforcement learning is autonomous driving.
Summary¶
Congratulations, you have made it through the article!
While reading the article, you met the three machine learning disciplines supervised, unsupervised, and reinforcement learning. You learned that supervised learning is used to teach a computer model what humans already know and unsupervised learning is applied if unknown patterns need to be discovered. Furthermore, examples for each machine learning subcategory were named to give you a first overview of the usefulness of machine learning.
I hope you enjoyed reading the article. Make sure to share it with your friends and colleagues. If you haven't already, follow me on Twitter, where I'm @DahlitzF, and subscribe to my newsletter, so you won't miss any future article.
Stay curious and keep coding!